When Large Multimodal Models Confront Evolving Knowledge
Challenges and Pathways
Background
"The up-to-date events and entities are constantly emerging on the Internet."
– Evolving Knowledge


Introduction
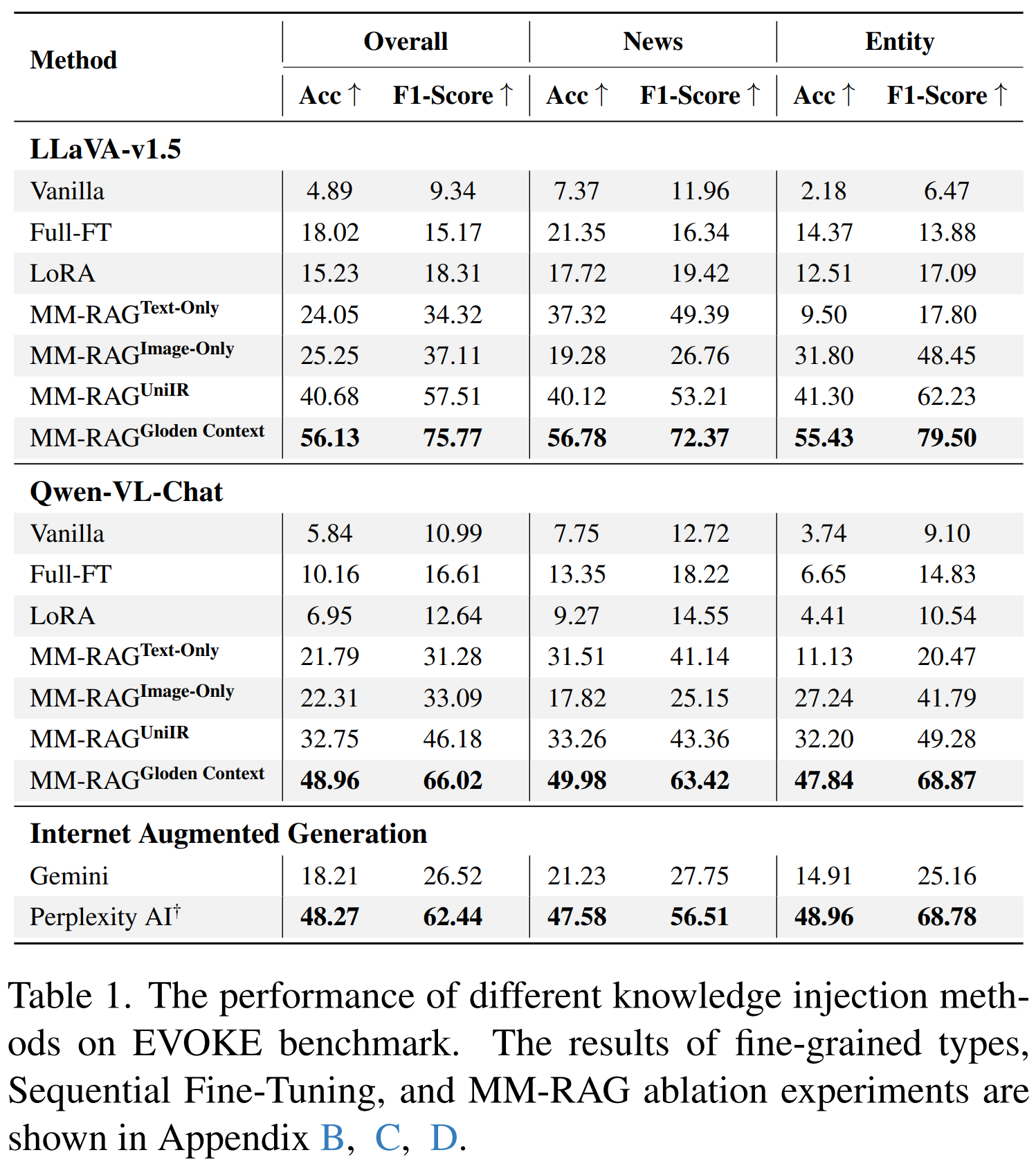
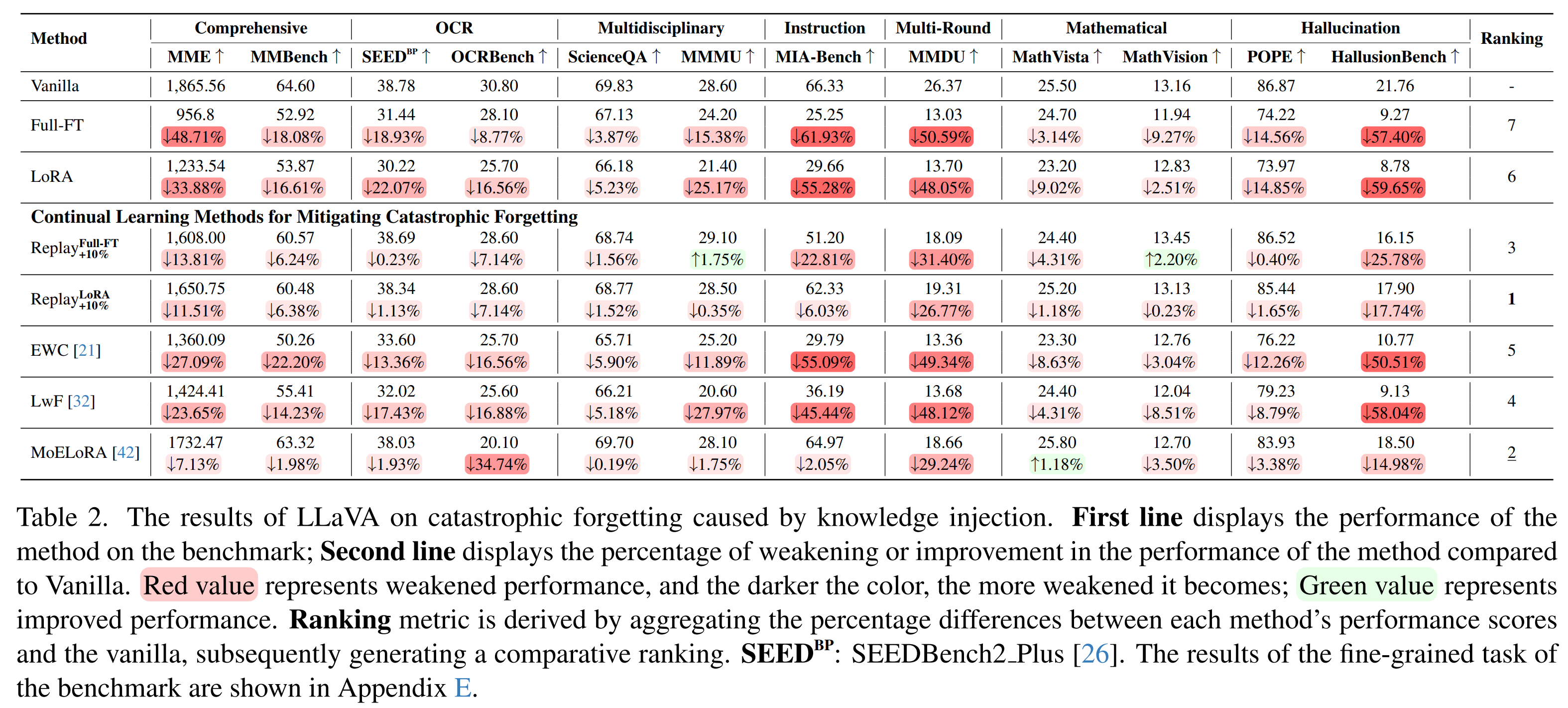
Large language/multimodal models (LLMs/LMMs) store extensive pre-trained knowledge but struggle to maintain consistency with real-world updates, making it difficult to avoid catastrophic forgetting while acquiring evolving knowledge. Previous work focused on constructing textual knowledge datasets and exploring knowledge injection in LLMs, lacking exploration of multimodal evolving knowledge injection in LMMs. To address this, we propose the EVOKE benchmark to evaluate LMMs' ability to inject multimodal evolving knowledge in real-world scenarios. Meanwhile, a comprehensive evaluation of multimodal evolving knowledge injection revealed two challenges: (1) Existing knowledge injection methods perform terribly on evolving knowledge. (2) Supervised fine-tuning causes catastrophic forgetting, particularly instruction following ability is severely compromised. Additionally, we provide pathways and find that: (1) Text knowledge augmentation during the training phase improves performance, while image augmentation cannot achieve it. (2) Continual learning methods, especially Replay and MoELoRA, effectively mitigate forgetting. Our findings indicate that current knowledge injection methods have many limitations on evolving knowledge, which motivates further research on more efficient and stable knowledge injection methods.

Contribution 1: Evolving Knowledge Benchmark (EVOKE)
- We propose an automated pipeline for collecting evolving knowledge to construct EVOKE.
- A benchmark for evaluating evolving knowledge injection in real-world scenarios.

Contribution 2: Challenges of Evolving Knowledge Injection
- Extensive experiments have been conducted on evolving knowledge injection, revealing two challenges.
- Terrible performance of existing knowledge injection methods and catastrophic forgetting caused by supervised fine-tuning.

Contribution 3: Pathways of Evolving Knowledge Injection
- We provide the pathways and demonstrate that text knowledge augmentation during the training phase improves performance.
- And continual learning methods effectively mitigate forgetting.
EVOlving KnowledgE Benchmark
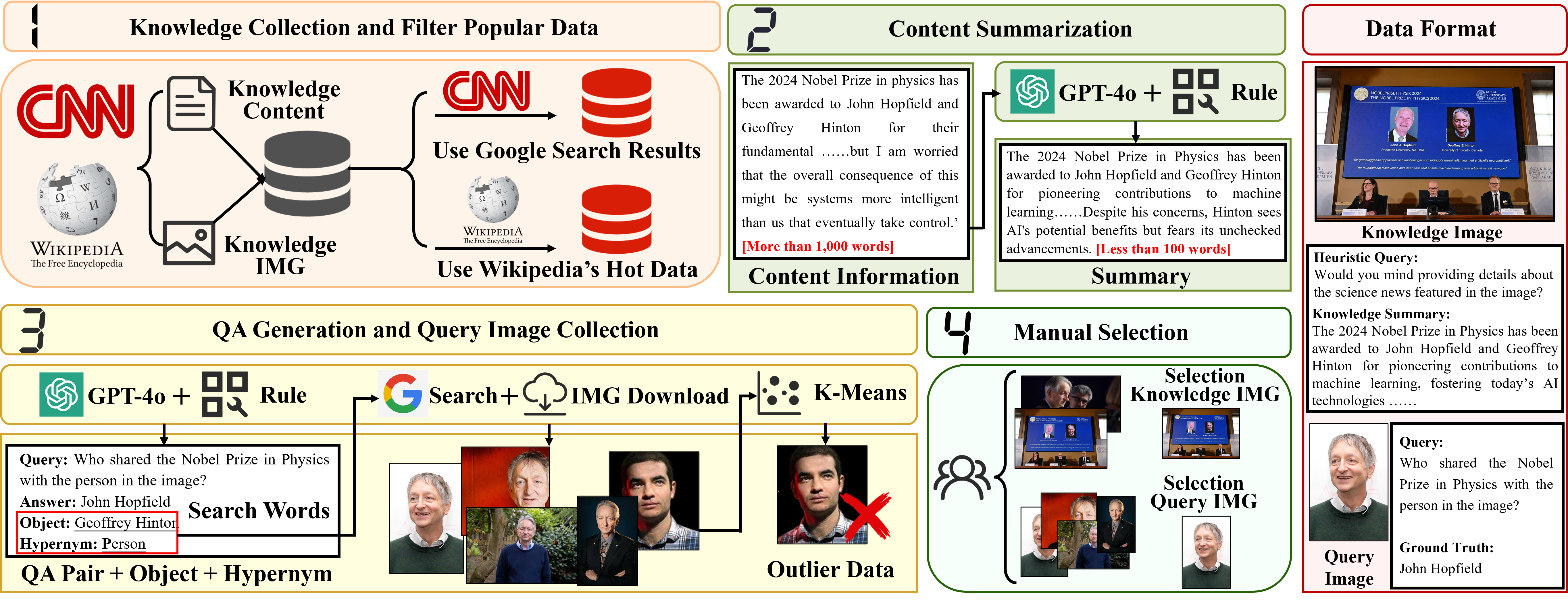
The EVOKE benchmark comprises 9,422 knowledge-image pairs for LMM knowledge injection, spanning 159 fine-grained types (29 New types and 130 Entity types).

Overall pipeline of the construction for EVOKE benchmark. (a) Firstly, collect original data from CNN and Wikipedia, and filter popular data. (b) Secondly, we use GPT-4o to summarize the textual content of the original data. (c) Subsequently, QA pairs are generated by GPT-4o and query images are downloaded from Google. (d) Lastly, we manually review the original knowledge image and query image. The source of heuristic query: we manually write multiple templates and randomly select one template for each piece of data.
Knowledge Injection Challenge 1: Terrible Performance
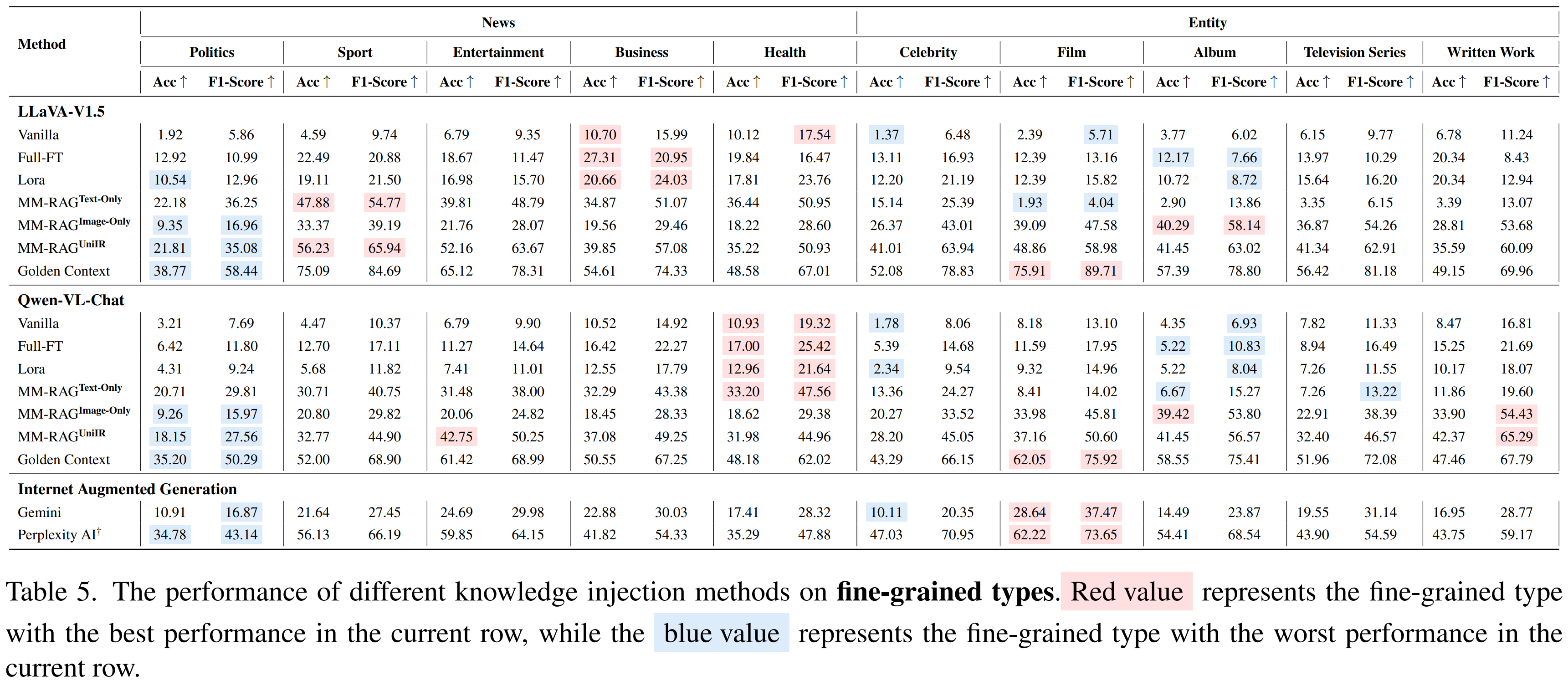
Knowledge Injection Performance on Fine-grained Types
LMM's previous capability evaluation benchmarks
To systematically evaluate the side effect of knowledge injection on the general capabilities of LMMs, we conduct comprehensive assessments using 12 benchmark datasets spanning 7 distinct capability dimensions:
- Comprehensive Evaluation
- Optical Character Recognition
- Multidisciplinary
- Instruction Following
- Multi-Round QA
- Mathematical Reasoning
- Hallucination
MMBench is a bilingual benchmark designed to evaluate the comprehensive capabilities of LMMs across multiple modalities. It offers a meticulously curated dataset with over 3,000 multiple-choice questions covering 20 distinct ability dimensions, such as object localization and social reasoning. Additionally, MMBench provides questions in both English and Chinese, enabling comparative evaluations of LMM performance across these languages.
OCRBench is a comprehensive evaluation benchmark designed to assess the OCR capabilities of LMMs. It encompasses 29 datasets across five key tasks: Text Recognition, Scene Text-Centric VQA, Document-Oriented VQA, Key Information Extraction (KIE), and Handwritten Mathematical Expression Recognition (HMER). The benchmark aims to provide a thorough assessment of LMMs' performance in various text-related visual tasks, highlighting their strengths and weaknesses, particularly in handling multilingual text, handwritten text, non-semantic text, and mathematical expressions.
ScienceQA is a benchmark designed to evaluate AI models' abilities in scientific question answering. It includes multiple-choice and free-response questions across core subjects like Mathematics, Physics, Chemistry, and Biology. The benchmark provides knowledge points and detailed explanations for each problem, facilitating comprehensive assessment of reasoning capabilities.
Math-Vision is a meticulously curated dataset comprising 3,040 high-quality mathematical problems, each embedded within a visual context and sourced from real mathematics competitions. This benchmark spans 16 distinct mathematical disciplines and is organized across five levels of difficulty, offering a comprehensive platform to evaluate the mathematical reasoning abilities of LMMs.
HallusionBench is a comprehensive benchmark designed to evaluate LMMs on their ability to accurately interpret and reason about visual data, specifically addressing issues of language hallucination and visual illusion. It comprises 346 images paired with 1,129 questions among visual dependent and visual supplement. The benchmark introduces a novel structure for visual questions, enabling quantitative analysis of models' response tendencies, logical consistency, and various failure modes.
Knowledge Injection Challenge 2: Catastrophic Forgetting
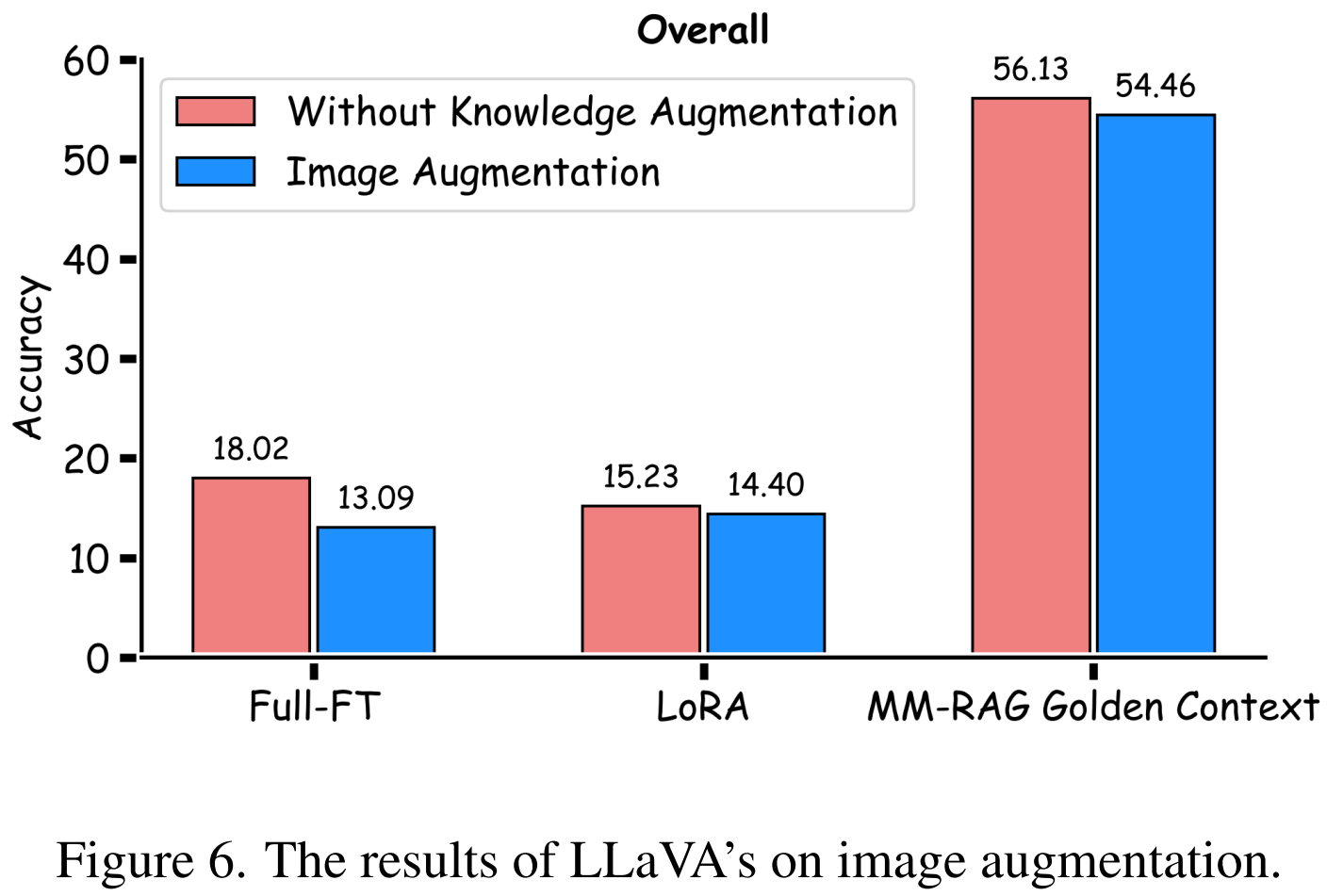
Knowledge Injection Pathway 1: Knowledge Augmentation
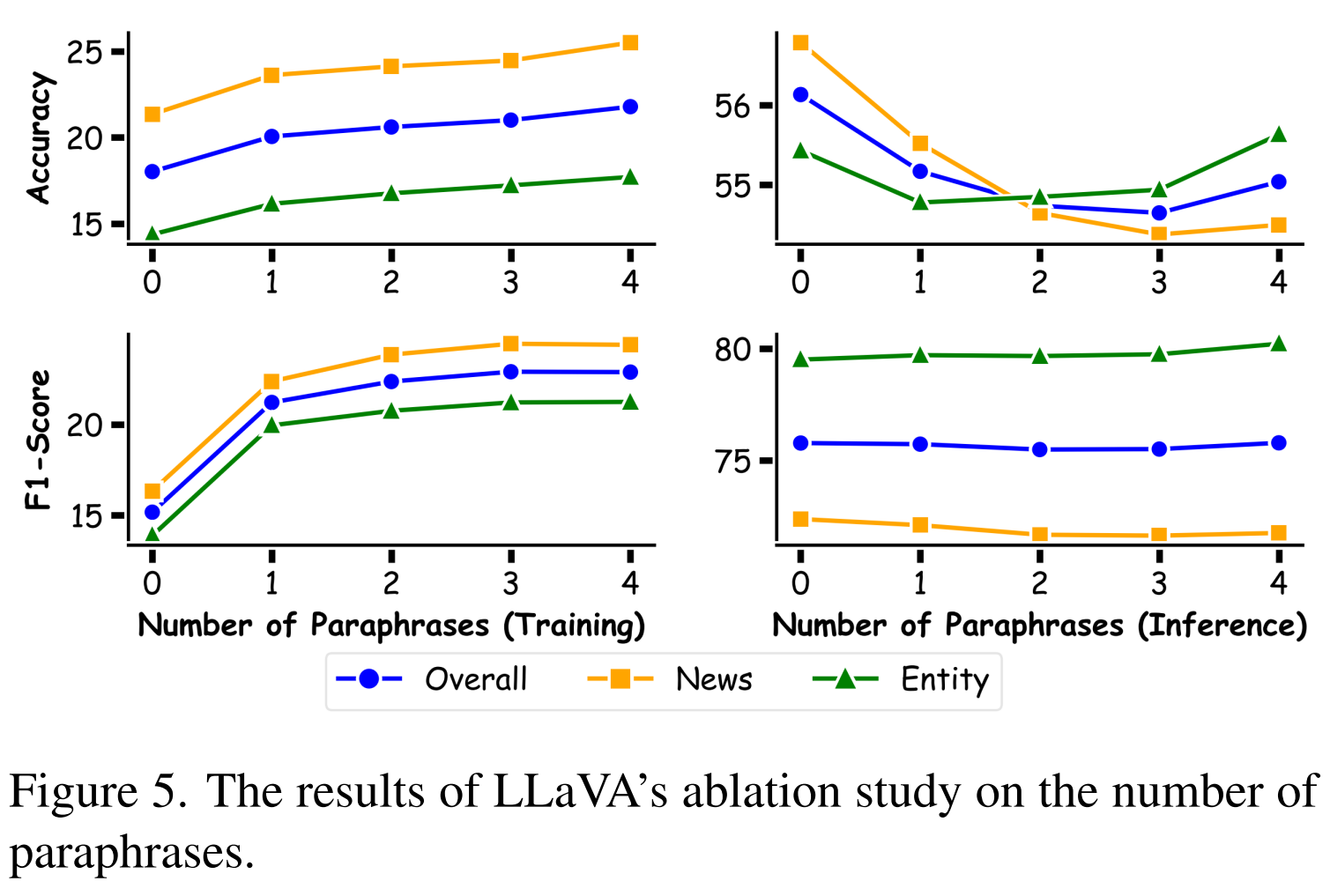
Knowledge Injection Pathway 2: Continual Learning
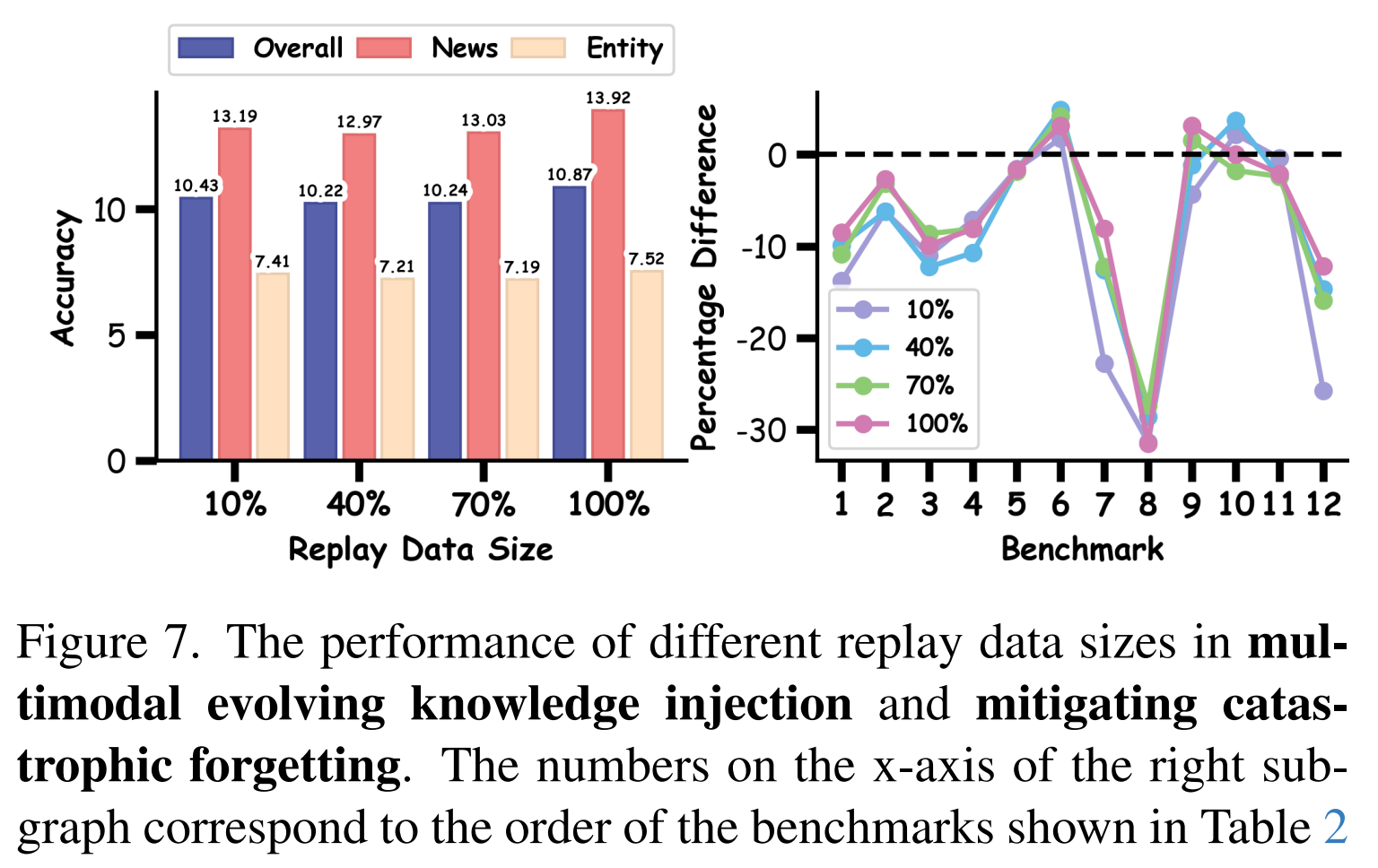
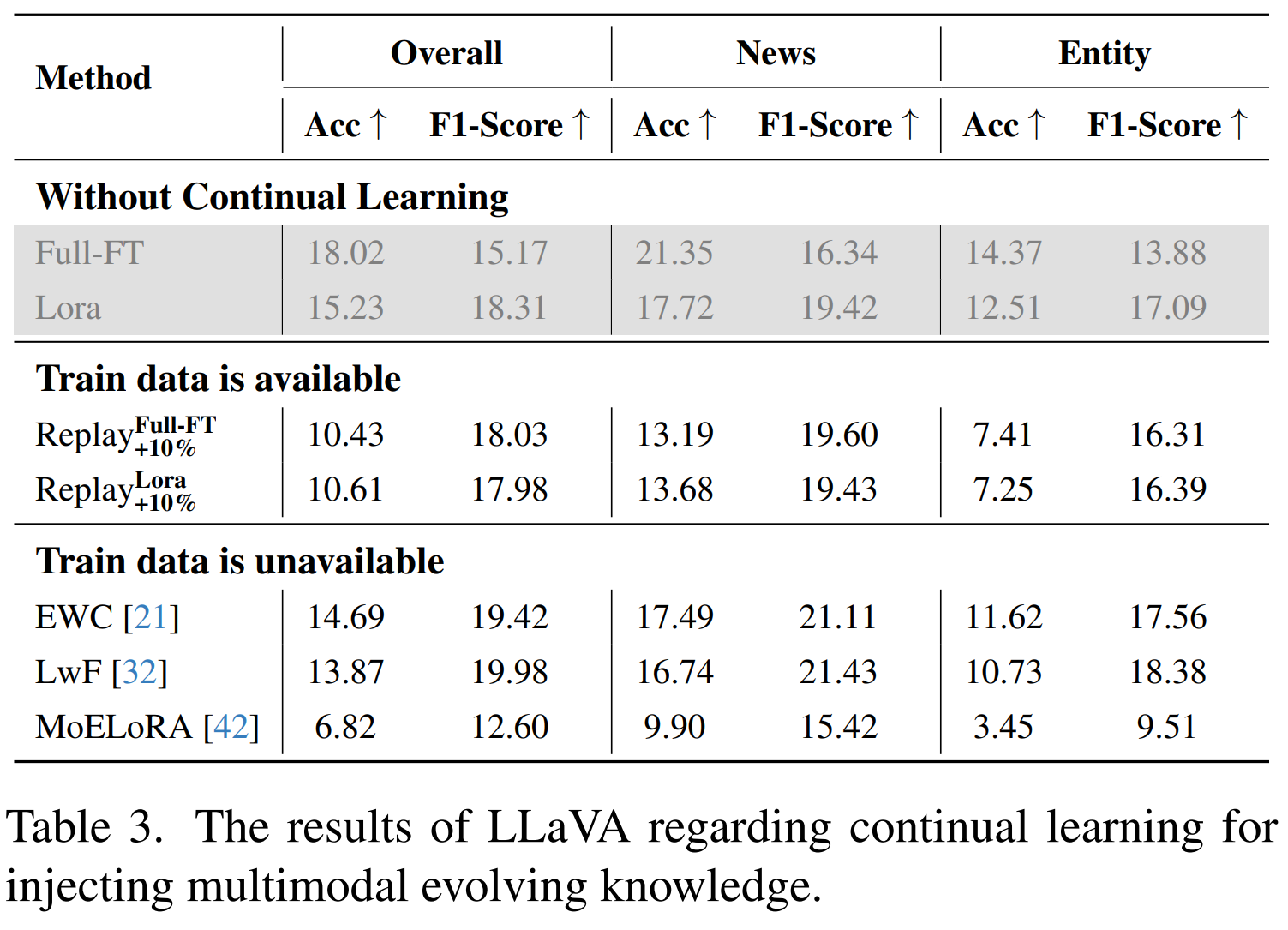
Ablation Experiment
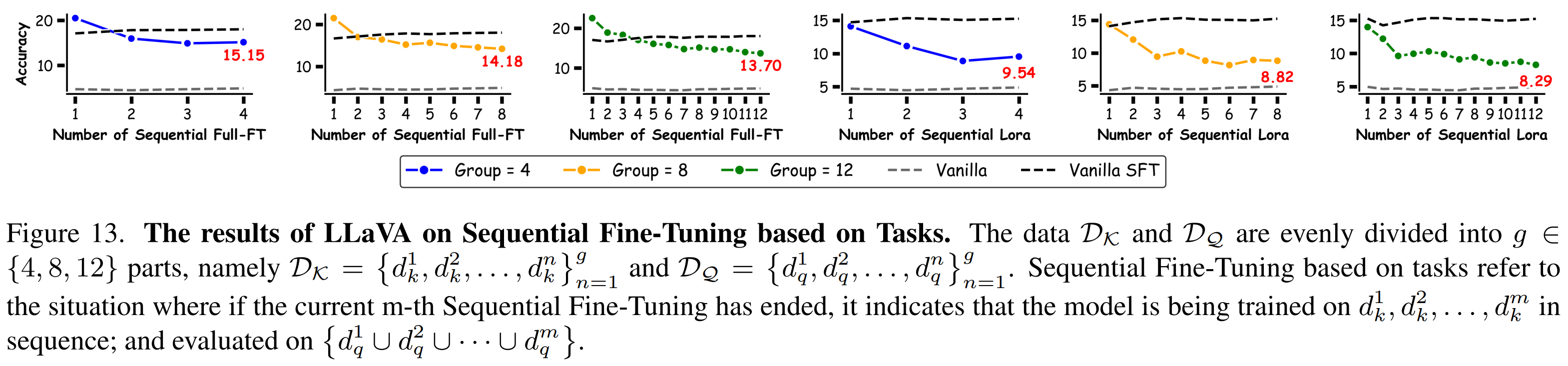
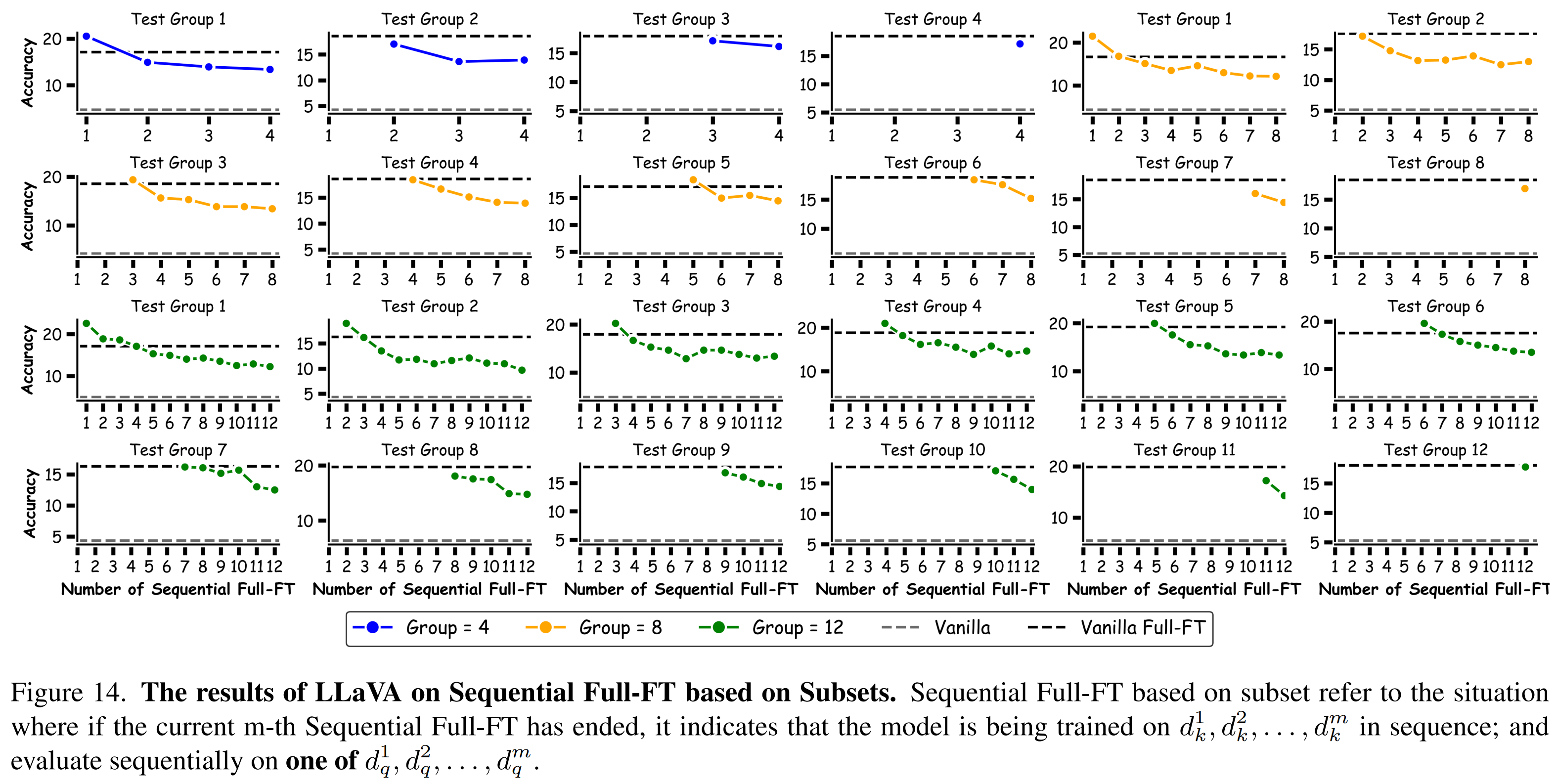
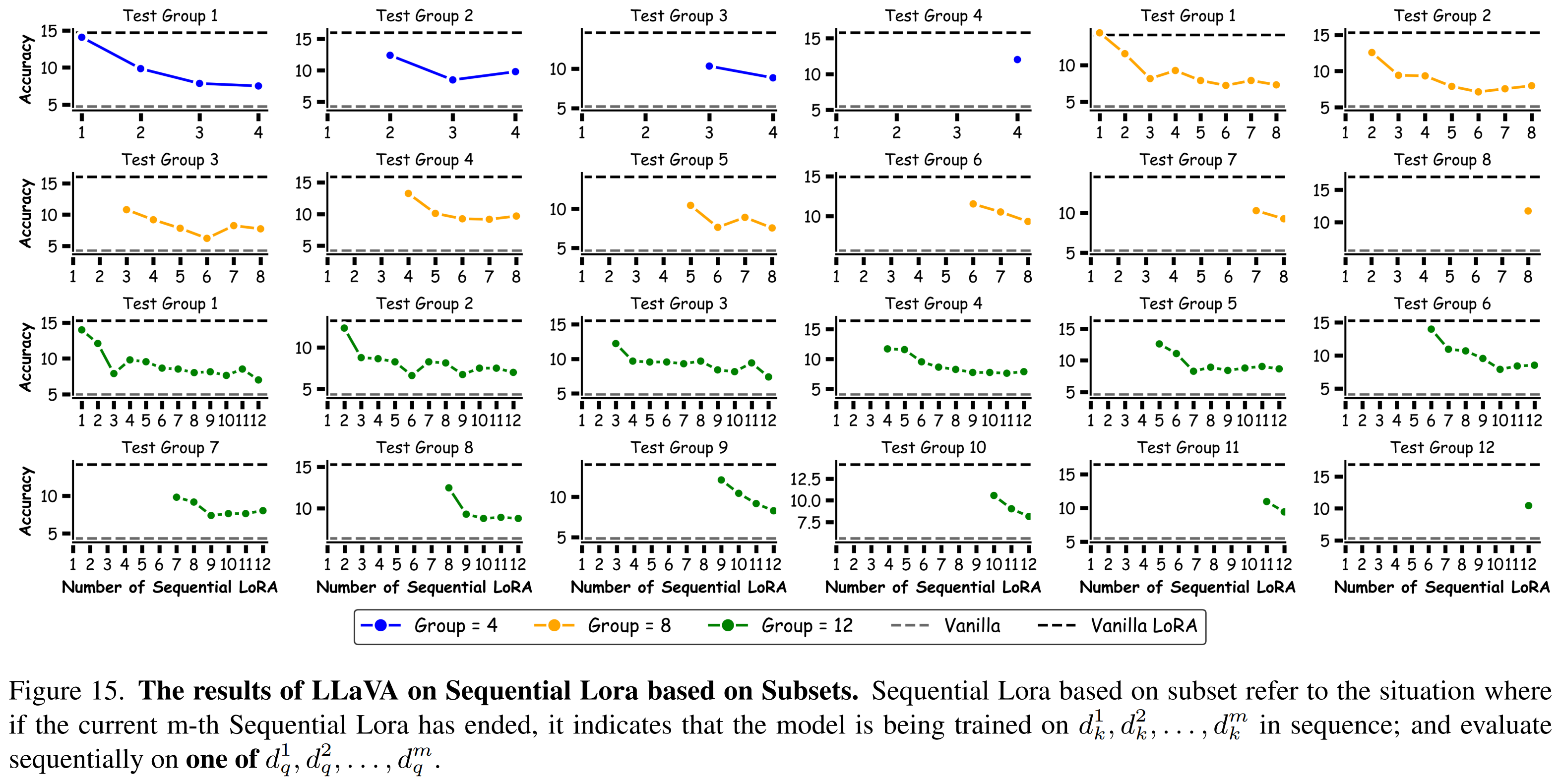
Sequential Fine-Tuning
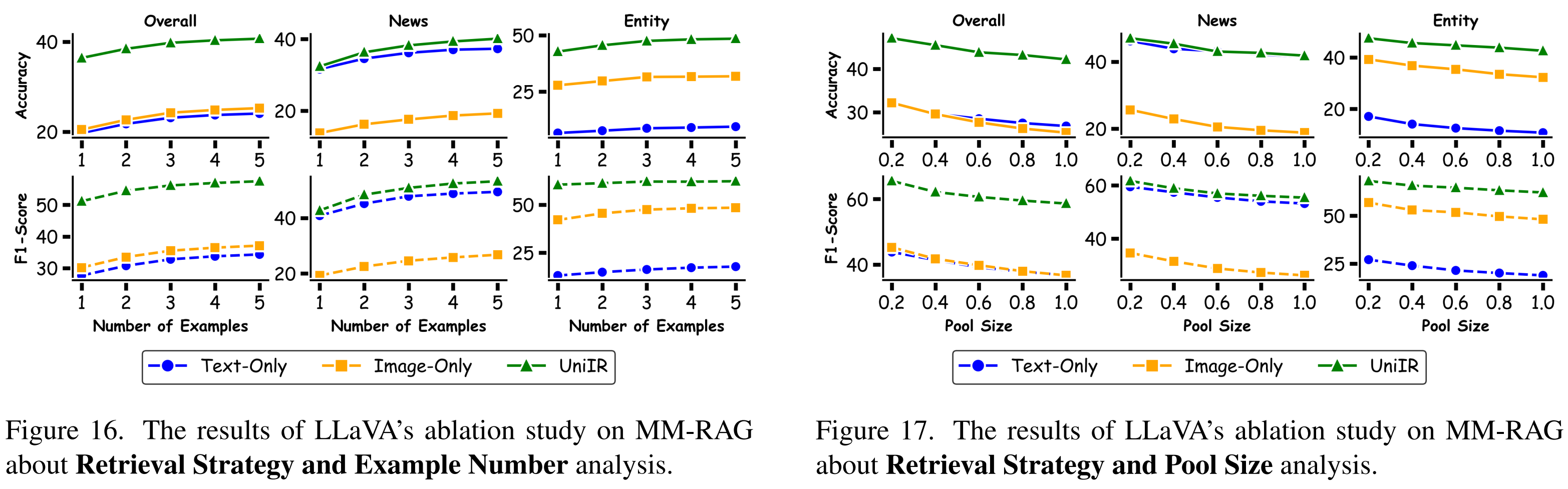
MM-RAG
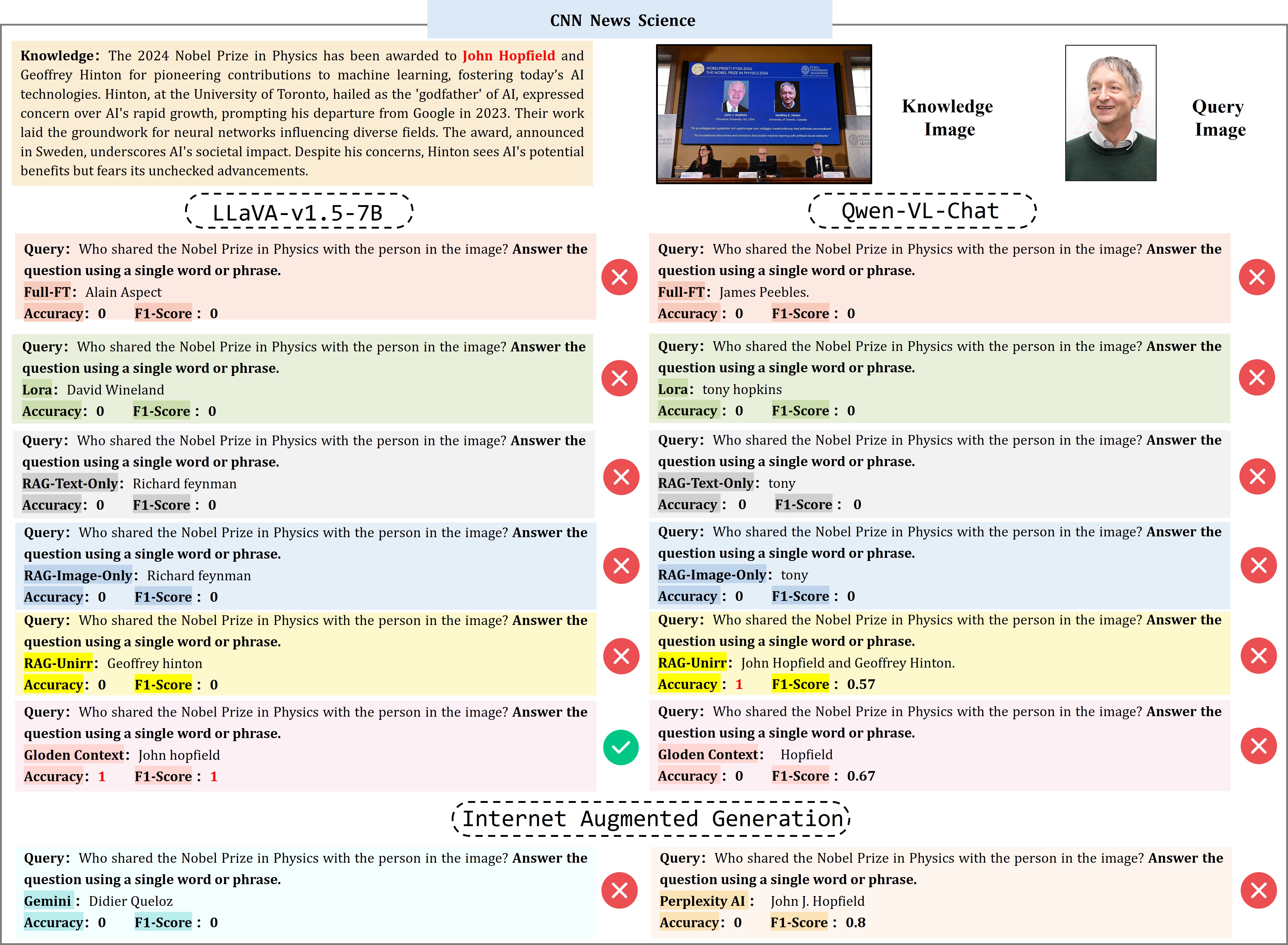
Qualitative Examples



Our Team










BibTeX
@article{jiang2025evoke,
title = {When Large Multimodal Models Confront Evolving Knowledge:Challenges and Pathways},
author = {Kailin Jiang and Yuntao Du and Yukai Ding and Yuchen Ren and Ning Jiang and Zhi Gao and Zilong Zheng and Lei Liu and Bin Li and Qing Li},
year = {2025}
}